一、引言
随着互联网的蓬勃发展,数据抓取(Web Scraping)已经成为了许多行业获取信息的核心技术。从电商监控到社交媒体分析,数据抓取几乎无处不在。然而,随着平台的反扒机制逐步加强,传统的IP抓取方式面临着被封禁、访问限制等问题。因此,动态住宅IP作为一种新型技术,凭借其隐蔽性和高效性,成为了数据抓取领域的一项突破性技术。
本文将详细探讨动态住宅IP在数据抓取中的作用,尤其是在TikTok平台上的实际应用,并给出一些操作建议。
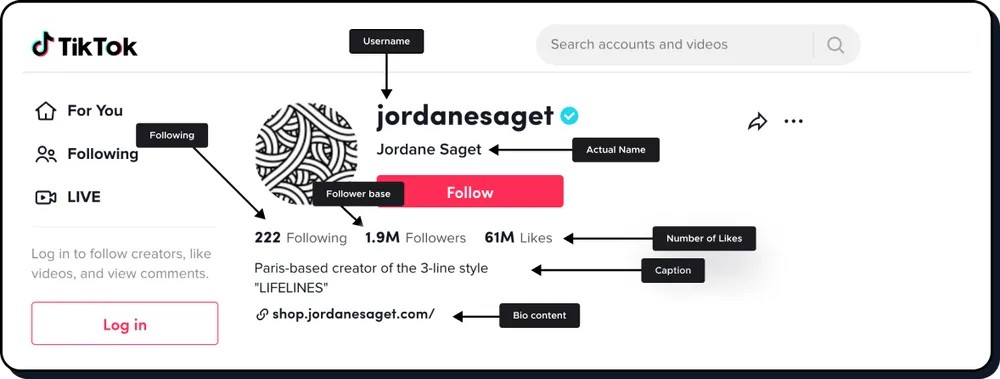
二、动态住宅IP的技术原理
1. 什么是动态住宅IP?
动态住宅IP是通过ISP(互联网服务提供商)提供的住宅IP来实现的,每个动态住宅IP代表的是一个普通家庭用户的网络地址。与传统的静态IP或数据中心IP不同,动态住宅IP能够通过不断变化的IP地址来模拟真实的用户行为,从而降低了被平台识别为自动化工具的风险。
2. 动态住宅IP的工作原理
动态住宅IP背后通常有一个大规模的IP池,每次访问时都会随机选择一个IP地址,并且该IP的有效性有限。随着IP的使用,系统会自动切换到新的IP地址,从而保证了数据抓取任务不会因频繁请求而被目标网站封禁。
3. 与传统IP的比较
静态IP:静态IP是固定不变的,因此一旦频繁请求,容易被识别为机器人流量,导致封禁。
数据中心IP:这些IP地址通常来自专门的数据中心,容易被目标平台识别并屏蔽。
动态住宅IP:具有高度的隐蔽性,因为这些IP地址来源于普通用户的家庭网络,能够模拟自然用户行为,不容易被识别为抓取工具。
三、动态住宅IP在数据抓取中的作用
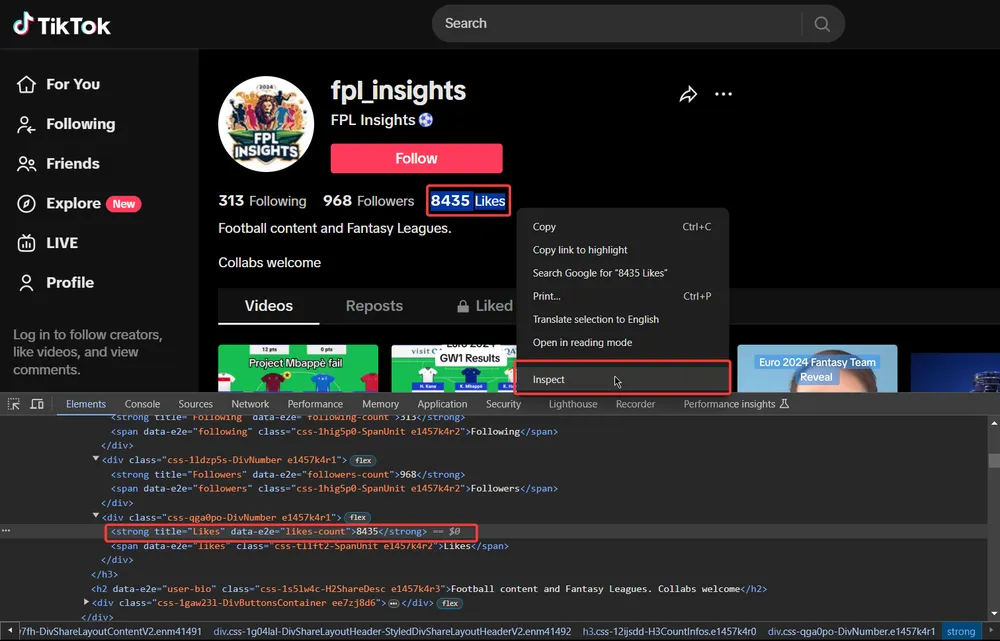
1. 防止封禁 🔒
大多数网站和平台会使用IP封禁技术来防止机器人抓取数据。当同一个IP频繁发起请求时,平台会认定这是机器行为,从而进行封禁。动态住宅IP通过更换IP地址,避免了同一IP的过度请求,能够有效防止封禁。
2. 提高抓取效率 ⚡
对于需要进行大量数据抓取的任务,动态住宅IP能够大大提高抓取的成功率。在进行大规模抓取时,IP切换技术使得抓取任务不会因为频繁请求而受限,这对于数据爬虫来说至关重要。
3. 模拟多地点行为 🌍
动态住宅IP使得抓取任务可以通过模拟全球范围内不同地区的用户行为进行。这样,你可以模拟不同国家或地区的用户访问,进行跨区域的数据抓取。这对于分析全球电商市场、社交平台行为等具有重要作用。
四、动态住宅IP的实际应用案例——以TikTok为例
1. 数据抓取目的
在TikTok平台上,数据抓取的需求主要集中在以下几个方面:
用户数据分析:通过抓取特定用户的点赞、评论、粉丝数等数据,进行用户行为分析。
视频内容分析:抓取热门视频的标签、评论、标题等内容,分析流行趋势。
竞争对手监控:通过抓取竞争对手的视频数据、用户互动,分析其内容策略和市场表现。
2. 操作建议
选择高质量的动态住宅IP提供商 🌐
选择一个可靠的动态住宅IP提供商至关重要。确保提供商能够提供全球范围的IP池,特别是覆盖目标市场的地区。例如,如果目标是获取美国的TikTok数据,可以选择提供美国IP的动态住宅IP服务商。
设置合理的抓取频率和IP切换间隔 ⏲️
频繁请求同一内容可能导致被平台封禁。建议设置较长的IP切换间隔,例如每10-20分钟切换一次IP。同时,抓取频率要保持合理,避免短时间内大量请求,模拟正常用户行为。
模拟真实用户行为 👤
TikTok等平台会监控异常行为模式。如果你希望获取某个视频或用户的互动数据,建议通过动态住宅IP模拟正常的用户行为,如滚动浏览、点赞、评论等。这样,平台就会将你的行为视为正常的用户行为,减少封禁风险。
跨地区抓取TikTok数据 🌏
动态住宅IP的优势在于可以模拟不同地区的用户行为。例如,如果你需要抓取全球范围的TikTok视频数据或评论内容,使用动态住宅IP可以轻松切换到不同地区的IP地址。通过这种方式,你可以抓取全球用户的互动数据,从而获得更全面的信息。
防止TikTok封禁账户 🚫
TikTok对频繁账户行为进行严格监控。为了避免因抓取操作而被封禁账户,可以采取以下措施:
使用不同的IP地址进行操作,避免在同一IP下频繁执行任务。
控制抓取频率,保持合理的访问间隔,避免一次性请求过多数据。
使用真实用户行为模拟,通过模拟正常的互动行为(如浏览、点赞、评论等),使得抓取行为更加自然。
3.代码实现建议
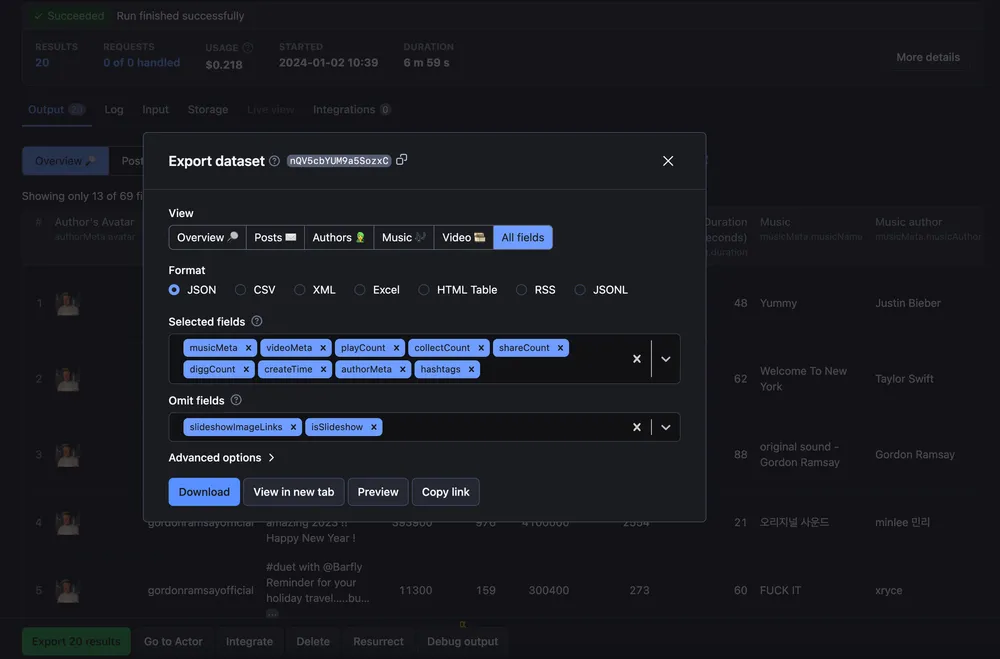
为了具体说明动态住宅IP在TikTok平台上的应用,以下是分步骤的代码实现建议。我们将通过动态住宅IP抓取TikTok的公共数据(如视频数据、用户互动等),并在抓取过程中采取防封禁措施。由于TikTok的反扒机制较为严格,本示例会结合Python与一些流行的库,展示如何利用动态住宅IP进行数据抓取。
1. 环境准备
首先,你需要安装以下Python库:
requests:用于发送HTTP请求。
BeautifulSoup:用于解析HTML页面。
time:用于控制抓取频率。
random:模拟用户行为。
fake_useragent:生成伪造的User-Agent。
bash
Copy
pip install requests beautifulsoup4 fake_useragent
接下来,我们会使用代理池和动态住宅IP进行请求。我们假设你已经有一个动态住宅IP的提供商,并且能够获取一个可用的代理池(例如proxy_list)。
2. 生成请求头(User-Agent)
模拟正常用户的请求,避免被TikTok检测为自动化工具。
python
Copy
from fake_useragent import UserAgent
# 生成随机的User-Agent
ua = UserAgent()
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9",
"Connection": "keep-alive",
"Accept-Encoding": "gzip, deflate, br"
}
3. 使用动态住宅IP代理池
我们假设你已经有一个代理池proxy_list,并将其用于抓取请求。每次请求时会随机选择一个代理,以防止IP封禁。
python
Copy
import random
# 假设proxy_list中存储了来自动态住宅IP服务商的代理
proxy_list = [
"http://123.45.67.89:8080",
"http://98.76.54.32:8080",
# 更多的代理IP...
]
# 随机选择一个代理
proxy = random.choice(proxy_list)
# 设置代理
proxies = {
"http": proxy,
"https": proxy
}
4. 发起请求并抓取数据
使用代理和请求头发起HTTP请求,并抓取TikTok的公开数据。这里以抓取某个TikTok视频页面的基础信息为例。
python
Copy
import requests
from bs4 import BeautifulSoup
import time
# TikTok视频页面的URL
url = "https://www.tiktok.com/@username/video/1234567890123456789"
# 发起GET请求
response = requests.get(url, headers=headers, proxies=proxies)
# 检查是否成功获取响应
if response.status_code == 200:
# 解析页面
soup = BeautifulSoup(response.text, "html.parser")
# 提取视频信息(例如:点赞数、评论数等)
try:
likes = soup.find("span", class_="like-count").text
comments = soup.find("span", class_="comment-count").text
shares = soup.find("span", class_="share-count").text
print(f"Likes: {likes}, Comments: {comments}, Shares: {shares}")
except AttributeError:
print("Failed to find data.")
else:
print(f"Failed to retrieve page: {response.status_code}")
# 控制抓取频率
time.sleep(random.uniform(5, 15)) # 随机间隔5-15秒
5. 模拟正常用户行为
为了进一步模拟正常用户的操作,避免抓取时被检测到,可以在抓取过程中进行间隔时间的控制,例如模拟用户的浏览间隔、点击、滚动等。通过time.sleep()可以实现。
python
Copy
# 模拟正常的用户间隔行为
time.sleep(random.uniform(3, 10)) # 3-10秒间隔
# 随机模拟不同时间段的访问,避免频繁请求
6. 处理IP切换和防封禁
为了防止IP封禁,我们可以通过设置合理的IP切换策略和请求间隔来避免引起TikTok的注意。这里我们采用了动态住宅IP代理池的轮换和间隔时间随机化。
python
Copy
# 设置一个IP池和合理的请求频率
def get_random_proxy():
return random.choice(proxy_list)
def fetch_data(url):
proxy = get_random_proxy()
proxies = {
"http": proxy,
"https": proxy
}
# 发起请求
response = requests.get(url, headers=headers, proxies=proxies)
if response.status_code == 200:
# 解析页面
soup = BeautifulSoup(response.text, "html.parser")
# 提取信息
likes = soup.find("span", class_="like-count").text
return likes
else:
print(f"Failed to retrieve page: {response.status_code}")
return None
# 控制抓取频率
for i in range(10): # 假设抓取10个视频
video_url = f"https://www.tiktok.com/@username/video/{i}"
likes = fetch_data(video_url)
print(f"Video {i}: Likes - {likes}")
# 每次请求后随机休眠,避免被检测
time.sleep(random.uniform(5, 15))
7. 处理请求限制与封禁
如果请求数量过多或频率过高,TikTok可能会暂时封禁你的IP或账户。因此,需要在抓取过程中做合理的频率控制和错误处理。
python
Copy
# 错误处理及IP封禁避免
try:
response = requests.get(url, headers=headers, proxies=proxies)
if response.status_code == 200:
print("Data retrieved successfully")
elif response.status_code == 403: # 如果被封禁
print("IP banned, switching proxy...")
proxy = get_random_proxy()
proxies = {"http": proxy, "https": proxy}
else:
print(f"Request failed with status code: {response.status_code}")
except requests.RequestException as e:
print(f"Request error: {e}")
8. 总结与注意事项
IP池管理:动态住宅IP的核心优势之一是能够通过IP池的轮换减少封禁的风险。要确保代理池的质量和稳定性。
请求频率控制:避免过于频繁的请求,模拟正常用户行为,设置合理的请求间隔(例如每个请求之间有随机的间隔时间)。
合法合规抓取:确保抓取数据时遵循相关平台的政策和法律法规,避免抓取过多敏感数据或侵犯用户隐私。
代理错误处理:在出现请求失败或被封禁的情况时,及时切换IP或增加延时,确保抓取任务的顺利进行。
通过以上步骤,你可以使用动态住宅IP来抓取TikTok的数据,同时确保避免封禁和提高抓取的成功率。
五、使用动态住宅IP时的注意事项

1. IP质量与选择 🔍
选择提供高质量、全球覆盖的动态住宅IP服务商非常关键(请搜索TTSOP,高质量动态住宅IP服务商)。IP质量直接影响抓取的成功率和稳定性,确保选择的服务商能提供高质量的IP池,并且支持多地区的IP访问。
2. 合规性与风险防范 ⚖️
在使用动态住宅IP进行数据抓取时,务必遵循平台的使用规定和相关法律法规。虽然动态住宅IP能够有效防止封禁,但依然需要避免违反平台的政策,例如抓取过于敏感的数据或滥用平台资源。
3. 抓取频率控制 📉
合理安排抓取任务的频率,避免过度请求导致平台封禁。设置适当的时间间隔和IP切换频率,以模拟正常的用户访问行为,避免引起平台反扒机制的警觉。
六、总结
动态住宅IP作为一种创新的抓取技术,凭借其灵活的IP切换机制和模拟真实用户的特点,在数据抓取中展现了巨大的潜力。尤其是在TikTok等平台上,动态住宅IP不仅可以提高抓取效率,避免封禁,还能够模拟跨地区用户行为,获取更多有价值的数据。
随着技术的不断发展,动态住宅IP将在数据抓取、市场监控、竞争分析等领域发挥更大的作用。通过合理配置和使用动态住宅IP,我们能够更加高效、安全地抓取所需数据,为各行各业的决策提供有力支持。






