随着互联网的发展,信息抓取(Web Scraping)已成为获取大量数据的重要手段。然而,传统的抓取方法常常会面临IP被封锁的问题,尤其是在抓取频繁或大规模数据时。为了解决这个问题,TTSOP的动态住宅IP(Residential IP)成为了一个理想的解决方案。本文将介绍TTSOP的动态住宅IP如何在网络信息抓取中应用,包括其原理和一些落地实践。
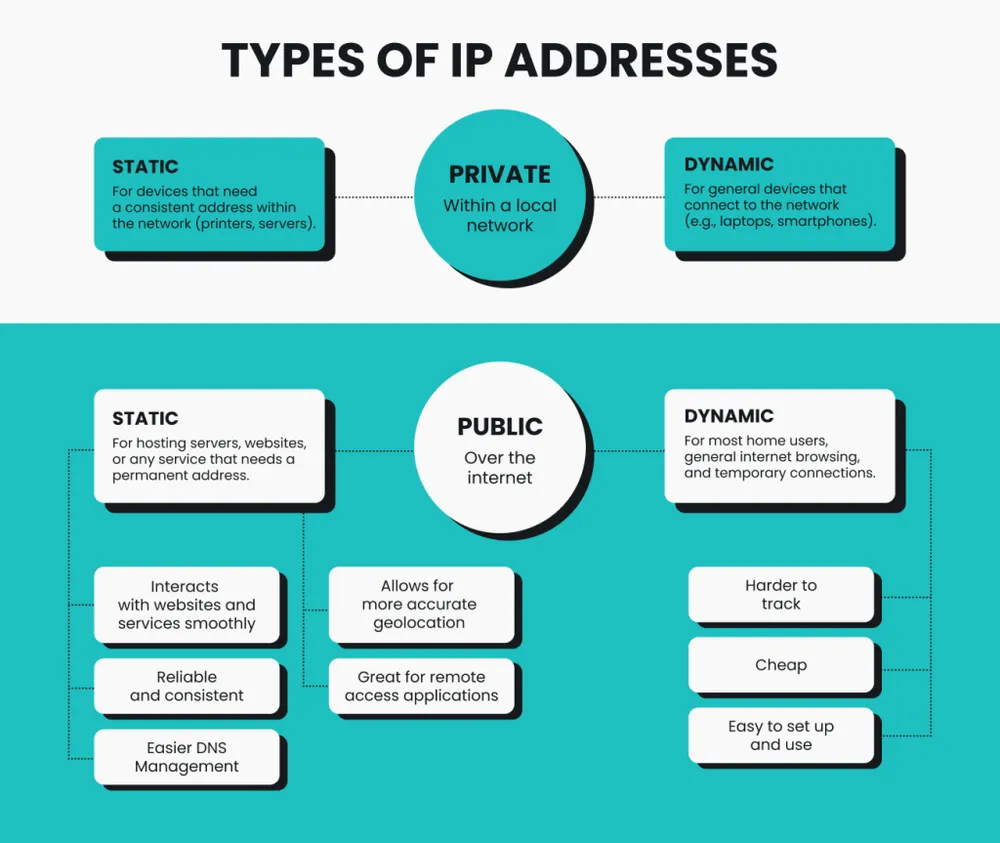
一、TTSOP动态住宅IP的原理

TTSOP(The Third-Party Service of Proxy)是一种提供动态住宅IP代理的服务,其核心优势在于使用了大量来自全球真实用户设备的IP地址。这些IP地址通过特定的技术手段分配给用户,以模拟真实的网络访问行为,从而有效避免了传统IP代理所面临的封锁和检测问题。
动态IP切换: TTSOP提供的动态住宅IP地址会定期切换,避免了因长期使用固定IP导致被目标网站检测和封禁。
真实用户IP模拟: 由于这些IP来自真实的家庭用户设备,网站往往无法检测到是通过代理进行的访问,大大提高了抓取的成功率。
地域多样性: TTSOP的IP池涵盖全球多个国家和地区,可以根据需要选择特定的IP来源,以模拟不同地域的用户访问。
二、动态住宅IP在网络信息抓取中的优势
避免封禁: 传统的数据抓取通常会被目标网站识别并封锁,尤其是频繁请求时。而通过使用动态住宅IP,网站无法通过IP判断抓取行为,从而减少封禁的风险。
高速抓取: 动态住宅IP的稳定性和速度比一般的代理IP更加可靠,适用于需要高频次、高并发抓取的场景。
地域切换: 在需要从不同地区收集数据时,TTSOP的动态住宅IP可以灵活切换IP位置,模拟不同国家或地区的用户行为,帮助用户绕过地域限制,获取全球数据。
三、如何使用TTSOP的动态住宅IP进行抓取
选择代理服务: 首先,注册并购买TTSOP的代理服务,根据抓取需求选择合适的IP池和地区。
配置代理: 在抓取程序中,配置TTSOP提供的代理地址和端口。通常,TTSOP会提供API接口或代理列表,用户可以根据文档配置抓取工具(如Python的
requests库、Scrapy、Selenium等)使用这些代理IP。管理动态IP切换: 在抓取过程中,可以设置定时切换IP,避免被目标网站检测到频繁使用同一IP。TTSOP通常会提供IP切换的频率控制工具,帮助用户实现高效的IP轮换。
处理异常与重试: 由于网络环境和目标网站的变化,抓取过程中可能会遇到IP被临时封禁或请求失败的情况。此时可以设置重试机制,自动切换IP或暂停一段时间再重试。
四、落地实践案例
案例1:电商价格监控
某电商平台需要每天抓取竞争对手的商品价格,并根据价格变化调整自己的营销策略。由于该平台对频繁访问其页面的IP进行封锁,因此直接使用常规IP进行抓取无法持续进行。通过使用TTSOP的动态住宅IP,电商团队能够以模拟真实用户的方式,从多个地域动态抓取数据,避免了被封禁的风险,同时确保数据的高频次抓取。
案例2:社交媒体数据分析
社交媒体平台对API的访问限制较多,而网页上的公开信息往往没有API接口。某数据分析公司利用TTSOP的动态住宅IP,成功抓取了多个社交媒体平台上的用户互动数据,并进行数据分析,得出市场趋势。由于使用了真实用户IP,平台并未检测到抓取行为,有效保证了数据抓取的稳定性和准确性。
对于使用TTSOP的动态住宅IP进行抓取的工具建议和核心代码,以下是一些具体的建议和代码示例:
工具建议
- Python库:
- requests:最常用的HTTP库,适用于简单的抓取需求。
- Scrapy:适用于大规模和复杂的抓取任务,提供了内置的代理池支持和强大的抓取控制。
- Selenium:适用于动态页面抓取,能够模拟浏览器操作,适合处理JavaScript渲染的页面。
- BeautifulSoup:与
requests一起使用,帮助解析和提取HTML页面内容。 - Puppeteer:用于无头浏览器抓取,适合需要渲染的复杂页面,支持控制页面交互。
- 代理管理工具:
- ProxyMesh:可以帮助管理代理池,自动切换IP地址。
- TTSOP API:如果TTSOP提供API,可以使用它来动态获取代理地址,自动切换IP。
核心代码示例
1. 使用 requests 和 TTSOP 动态住宅IP进行数据抓取
首先,假设您已从TTSOP获取代理IP和API接口,接下来在Python中实现抓取。
python
Copy code
import requests
from bs4 import BeautifulSoup
# 配置TTSOP动态住宅IP代理
proxy = {
'http': 'http://username:password@dynamic_ip_address:port',
'https': 'https://username:password@dynamic_ip_address:port',
}
# 目标URL
url = 'https://www.example.com/target-page'
# 发送HTTP请求
response = requests.get(url, proxies=proxy)
# 检查请求是否成功
if response.status_code == 200:
# 解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取所需的数据
data = soup.find_all('div', class_='target-class')
for item in data:
print(item.get_text())
else:
print(f"请求失败,状态码:{response.status_code}")
核心步骤:
在代码中配置了TTSOP动态住宅IP(包括用户名、密码和代理IP地址)。
使用
requests发送请求,并将代理配置传入proxies参数。成功获取网页内容后,使用
BeautifulSoup解析并提取需要的数据。
2. 使用 Scrapy 和 TTSOP 动态住宅IP抓取
Scrapy是一个更适合大规模数据抓取的框架,提供了很多抓取控制功能,比如自动切换IP、模拟请求头等。
创建 Scrapy 项目:
bash Copy code scrapy startproject ttsop_scraping cd ttsop_scraping在
settings.py中配置代理:python Copy code
设置代理池
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 1,
'ttsop_scraping.middlewares.ProxyMiddleware': 100,
}
配置代理(TTSOP提供的动态住宅IP)
PROXY = 'http://username:password@dynamic_ip_address:port'
```
- 创建
middlewares.py以控制代理的切换:python Copy code import random
class ProxyMiddleware:
def init(self):
self.proxies = [
'http://username:password@dynamic_ip_address_1:port',
'http://username:password@dynamic_ip_address_2:port',
'http://username:password@dynamic_ip_address_3:port',
# 更多代理IP
]
def process_request(self, request, spider):
# 随机选择一个代理IP
proxy = random.choice(self.proxies)
request.meta['proxy'] = proxy
```
- 编写
spider抓取数据:python Copy code import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example_spider'
start_urls = ['https://www.example.com/target-page']
def parse(self, response):
# 提取所需数据
data = response.css('div.target-class::text').getall()
for item in data:
yield {'data': item}
```
- 运行 Scrapy 项目:
bash Copy code scrapy crawl example_spider
核心步骤:
在
settings.py中配置代理中间件,确保抓取请求使用TTSOP的动态住宅IP。使用
ProxyMiddleware中间件自动切换代理IP。使用Scrapy框架的
parse方法提取数据。
3. 使用 Selenium 和 TTSOP动态住宅IP抓取
Selenium适合抓取动态加载的网页或需要用户交互的页面。
python
Copy code
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
import time
# 配置代理
proxy = Proxy()
proxy.proxy_type = ProxyType.MANUAL
proxy.http_proxy = 'dynamic_ip_address:port'
proxy.ssl_proxy = 'dynamic_ip_address:port'
# 配置Chrome浏览器的代理设置
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless') # 无头模式
chrome_options.add_argument('--disable-gpu') # 禁用GPU加速
# 设置代理
chrome_options.add_argument(f'--proxy-server=http://{proxy.http_proxy}')
# 启动浏览器
driver = webdriver.Chrome(options=chrome_options)
# 打开目标网页
driver.get('https://www.example.com/target-page')
# 等待页面加载
time.sleep(3)
# 提取数据
data = driver.find_elements_by_css_selector('div.target-class')
for item in data:
print(item.text)
# 关闭浏览器
driver.quit()
核心步骤:
使用
Selenium启动浏览器并配置代理(通过TTSOP动态住宅IP)。加载页面并提取所需的动态数据。
小结
通过结合TTSOP的动态住宅IP和合适的抓取工具(如requests、Scrapy、Selenium等),您可以高效地进行大规模网络信息抓取,并避免封IP的风险。抓取过程中应注意代理的管理与切换,以及遵守目标网站的爬虫规则。
五、注意事项与最佳实践

遵守网站的爬虫规则: 在进行抓取时,必须遵循目标网站的
robots.txt文件中的规定,尽量避免对网站造成过大的负担。IP切换频率的控制: 使用动态住宅IP时,建议根据抓取频率适当调整IP切换频率。过于频繁或不规则的切换可能会导致抓取失败。
数据去重与过滤: 在抓取大量数据时,可能会遇到重复信息。可以通过设定规则对数据进行去重处理,避免无效数据的积累。

六、结论
TTSOP的动态住宅IP为网络信息抓取提供了一个稳定、安全且高效的解决方案。通过模拟真实用户的行为,动态IP能够避免封禁问题,提供更高的抓取成功率。在实际应用中,合理配置IP切换、监控抓取任务以及遵循目标网站的规则,是确保抓取效果和效率的关键。






